The scraper (source) is pretty simple. The process is:
That second step took quite a bit of examining of smugmug's pages. Currently all the pages I am interested in working with are using the elegant style, so that's the only one I worked with. Things learned:
| Table Number | Function |
|---|---|
| 1 | The banner across the top including the search and shopping icons |
| 1:2 | Layout for the banner |
| 3 | Header text "Marc Valentin's galleries" |
| 4 | Page intro with main thumbnail and description |
| 5 | Empty |
| 6 | Empty |
| 7 | Holder for galleries |
| 7:8 | Header for all the galleries |
| 7:9 | Left gallery in first row (Christmas) |
| 7:9:10 | Gallery desciption |
| 7:11 | Right gallery in first row (Halloween) |
| 7:11:12 | Gallery description |
| 7:13,7:17,1:21,7:25,7:29 | Left gallery |
| 7:15,7:19,1:23,7:27 | Right gallery |
| 31 | Empty |
| 32 | Photos by keyword |
| 32:33 | Photos by keyword header |
| 34 | Empty |
| 35 | Empty |
| 36 | Bottom navbar |
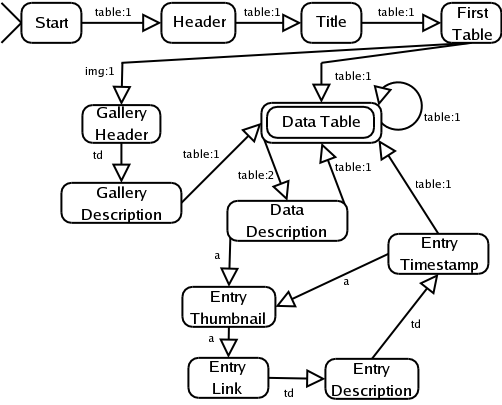
My information is limited, but as best I can tell breaking stuff up by tables should work pretty well. I think I'll do the program as a state machine. The transitions will be a combination of tag and depth. So the notation is [tag]:[class depth], so table:2 would be a transition on a table which is nested inside another table. The actual depth in the tree might be something like 5 for things like <html>, <body> and <td>. The 2 means it is a second level table. Additionally, there are arbitrarily many ignored tags. If a transition is not defined for an input, it is just ignored.
I'm pretty sure this will work and each section is atomic. Meaning, if I am buffing the output from the CDATA sections, I can clear the buffer before entering each state and on exit I won't have collected any extra garbage.
The program is working for the main page, it seems. Unfortunately I've already blown a day on this project and I've just discovered a XML-RPC interface to the site. Dammit. Oh well, I'll continue later…